


AI Probability Trees - Joe Carlsmith (2022)
Summaries are good, actually

I am reviewing the thoughts of AI experts on what they think will happen with AI. This is a summary of Joe Carlsmith’s thoughts from his paper. AI risk scares me but often I feel pretty disconnected from it. This has helped me think about it.
Here are Carlsmith’s thoughts in brief (he no longer fully endorses these):
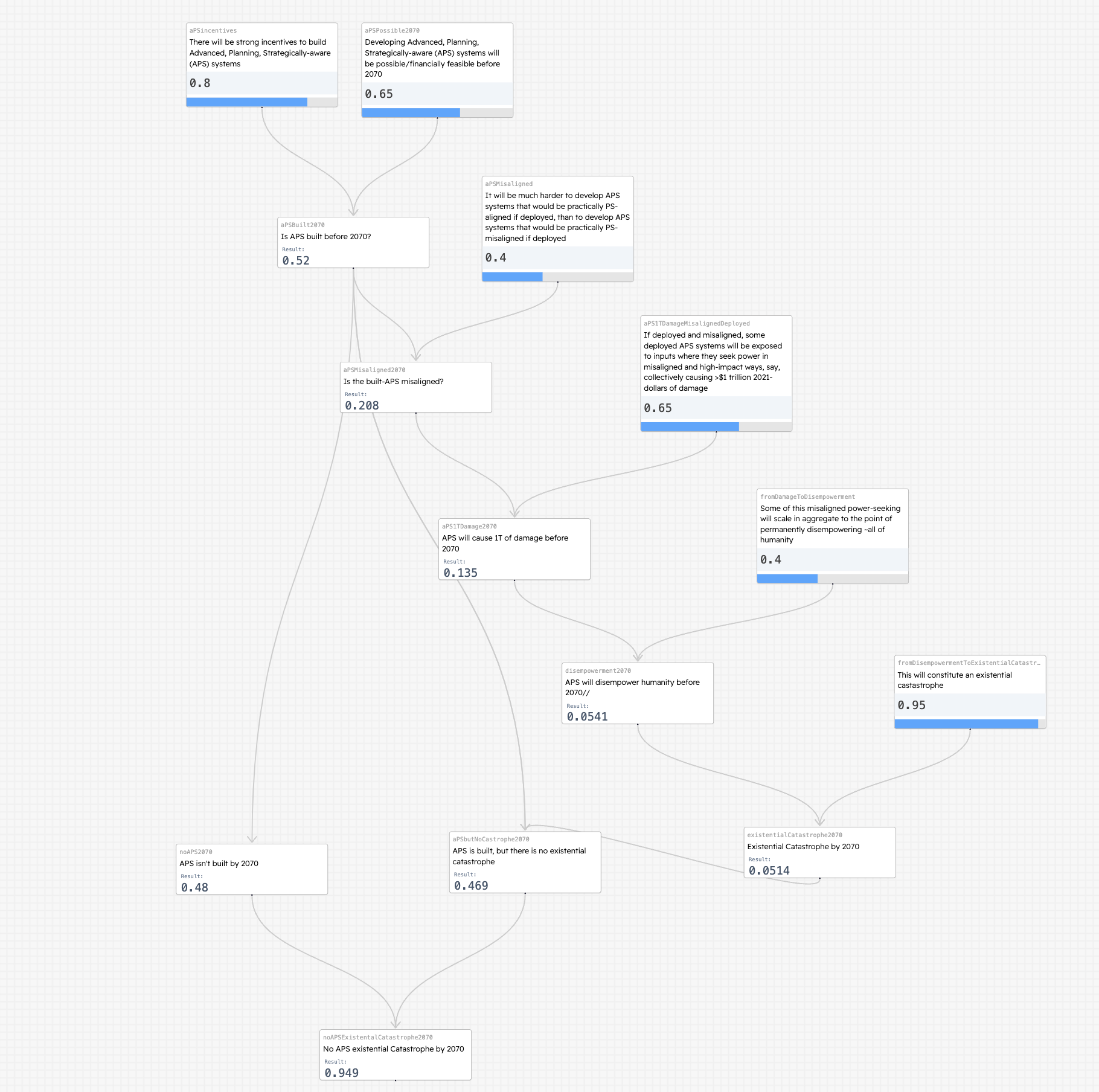
Will it become possible to build Carlsmith’s version of AGI by 2070 (65%)
Carlsmith’s standard is outperforms the best humans at advanced tasks, can plan and has accurate models of the world
There will be incentives to build such systems (80%)
It will be much harder to build aligned systems than ones that just seem aligned (40%)
Some misaligned systems will cause $1T of damage (65%)
Such misaligned power seeking will permanently disempower humanity (40%)
This will constitute existential catastrophe (95%)
Carlsmith also made a video of his paper here.
Longer explanations
What kind of AI is Carlsmith forecasting? What is APS?
Carlsmith uses the term APS rather than AGI.
Advanced capability: they outperform the best humans on some set of tasks which when performed at advanced levels grant significant power in today’s world (tasks like scientific research, business/military/political strategy, engineering, and persuasion/manipulation).
Agentic planning: they make and execute plans, in pursuit of objectives, on the basis of models of the world.
Strategic awareness: the models they use in making plans represent with reasonable accuracy the causal upshot of gaining and maintaining power over humans and the real-world environment.
Statement (Confidence)
Joe's Commentary (abridged with ...)
My commentary
By 2070, it will become possible and financially feasible to build APS (Advanced, Planning, Strategically-aware) systems (65%)
Joe’s commentary: This comes centrally from my own subjective forecast of the trajectory of AI progress (not discussed in this report), which draws on various recent investigations at Open Philanthropy, along with expert (and personal) opinion.
My commentary: It’s hard to compare this to say, Metaculus forecasts because Carlsmith’s APS is much more advanced than the AGI desribed here
Carlsmith talks about outperforming the best humans in a range of tasks - scientific research, business/military/political strategy and persuasion manipulation.
Metaculus requires a 2-hour adversarial turing test (current AIs may already pass this), 90% mean accuracy across some expert task set, 90% on an interview dataset and general robotic capabilities.
It seems to me that Carlsmith is just pointing at a much more competent thing, so it’s unsurprising that his confidence is lower in that timescale. Metaculus is currently at 2032 for its version.
There will be strong incentives to build APS systems, conditional on previous question (80%)
Joe’s commentary: This comes centrally from an expectation that agentic planning and strategic awareness will be either necessary or very helpful for a variety of tasks we want AI systems to perform.
I also give some weight to the possibility that available techniques will push towards the development of systems with these properties; and/or that they will emerge as byproducts of making our systems increasingly sophisticated (whether we want them to or not).
The 20% on false, here, comes centrally from the possibility that the combination of agentic planning and strategic awareness isn’t actually that useful or necessary for many tasks—including tasks that intuitively seem like they would require it…
For example, perhaps such tasks will mostly be performed using collections of modular/highly specialized systems that don’t together constitute an APS system.My commentary: None
It will be much harder to develop APS systems that would be practically PS-aligned if deployed, than to ones that seem PS-aligned, conditional on previous questions (40%)
Practically PS-aligned: Carlsmith calls systems “practically PS-aligned” if they don’t engage in misaligned power-seeking on any of the inputs it will in fact receive as opposed to fully PS aligned, which is on any inputs.
Full text: It will be much harder to develop APS systems that would be practically PS-aligned if deployed, than to develop APS systems that would be practically PS-misaligned if deployed (even if relevant decision-makers don’t know this), but which are at least superficially attractive to deploy anyway (Conditional on previous questions)Joe’s commentary: I expect creating a fully PS-aligned [that it won’t engage in misaligned power-seeking behaviour under any inputs] APS system to be very difficult, relative to creating a less-than-fully PS-aligned one with very useful capabilities…
However, I find it much harder to think about the difficulty of creating a system that would be practically PS-aligned, if deployed, relative to the difficulty of creating a system that would be practically PS-misaligned, if deployed, but which is still superficially attractive to deploy...
[Carlsmith discusses some areas of the problem]
I expect problems with proxies and search to make controlling objectives harder; and I expect barriers to understanding (along with adversarial dynamics, if they arise pre-deployment) to exacerbate difficulties more generally; but even so, it also seems possible to me that it won’t be “that hard” (by the time we can build APS systems at all) to eliminate many tendencies towards misaligned power-seeking (for example, it seems plausible to me that selecting very strongly against (observable) misaligned power-seeking during training goes a long way), conditional on retaining realistic levels of control over a system’s post-deployment capabilities and circumstances (though how often one can retain this control is a further question).
Beyond this, though, I’m also unsure about the relative difficulty of creating practically PS-aligned systems, vs. creating systems that would be practically PS-misaligned, if deployed, but which are still superficially attractive to deploy. One commonly cited route to this is via a system actively pretending to be more aligned than it is. This seems possible, and predictable in some cases; but it’s also a fairly specific behavior, limited to systems with a particular pattern of incentives (for example, they need to be sufficiently non-myopic to care about getting deployed, there need to be sufficient benefits to deployment, and so on), and whose deception goes undetected. It’s not clear to me how common to expect this to be, especially given that we’ll likely be on the lookout for it. More generally, I expect decision-makers to face various incentives (economic/social backlash, regulation, liability, the threat of personal harm, and so forth) that reduce the attraction of deploying systems whose practical PS-alignment remains significantly uncertain. And absent active/successful deception, I expect default forms of testing to reveal many PS-alignment problems ahead of time.
That said, even absent active/successful deception, there are a variety of other ways that systems that would be practically PS-misaligned if deployed can end up superficially attractive to deploy anyway: for example, because they demonstrate extremely useful/profitable capabilities, and decision-makers are wrong about how well they can predict/control/incentivize the systems in question; and/or because externalities, dysfunctional competitive dynamics, and variations in caution/social responsibility lead to problematic degrees of willingness to knowingly deploy possibly or actually practically PS-misaligned systems (especially with increasingly powerful capabilities, and in increasingly uncontrolled and/or rapidly changing circumstances).My Commentary: Carlsmith suggests a number of sliders going on under the surface, of hidden variables:
the number of practically PS-aligned systems vs the number that seem to be so
How valuable these systems are
Political pressures of the actors involved
How clearly we are searching for the end states that are harmful to us
I agree I am not convinced by people who are really certain in either direction here.
Some deployed APS systems will be exposed to inputs where they seek power in misaligned and high-impact ways (say, collectively causing >$1 trillion 2021-dollars of damage), conditional on previous questions (65%)
Joe’s commentary: In particular, I think that once we condition on 2 and 3, the probability of high-impact post-deployment practical alignment failures goes up a lot, since it means we’re likely building systems that would be practically PS-misaligned if deployed, but which are tempting—to some at least, especially in light of the incentives at stake in 2—to deploy regardless. The 35% on this premise being false comes centrally from the fact that
(a) I expect us to have seen a good number of warning shots before we reach really high-impact practical PS-alignment failures, so this premise requires that we haven’t responded to those adequately,
(b) the time-horizons and capabilities of the relevant practically PS-misaligned systems might be limited in various ways, thereby reducing potential damage, and
(c) practical PS-alignment failures on the scale of trillions of dollars (in combination) are major mistakes, which relevant actors will have strong incentives, other things equal, to avoid/prevent (from market pressure, regulation, self-interested and altruistic concern, and so forth).
However, there are a lot of relevant actors in the world, with widely varying degrees of caution and social responsibility, and I currently feel pessimistic about prospects for international coordination (cf. climate change) or adequately internalizing externalities (especially since the biggest costs of PS-misalignment failures are to the long-term future). Conditional on 1-3 above, I expect the less responsible actors to start using APS systems even at the risk of PS-misalignment failure; and I expect there to be pressure on others to do the same, or get left behind.My commentary: All I’d note here is that by some definitions current humans are misaligned and still we live in a world with better outcomes for us over time. It seems underrated that there will be systems competing with one another and so while the butcher and baker are selfish, we will still get our dinner. This seems a bit optimistic to me, but it should count for a bit. The real world does, surprisingly, work like this.
To expand a bit, trying to cause a trillion $ of damage might just pose too great a risk when we can instead be paid off in food, human connection and computer games. Why risk it?
Some of this misaligned power-seeking will scale (in aggregate) to the point of permanently disempowering ~all of humanity conditional on previous questions (40%)
Joe’s commentary: There’s a very big difference between >$1 trillion dollars of damage (~6 Hurricane Katrinas), and the complete disempowerment of humanity; and especially in slower takeoff scenarios, I don’t think it at all a foregone conclusion that misaligned power-seeking that causes the former will scale to the latter. But I also think that conditional on reaching a scenario with this level of damage from high-impact practical PS-alignment failures (as well as the other previous premises), things are looking dire. It’s possible that the world gets its act together at that point, but it seems far from certain.
My commentary: None
This will constitute an existential catastrophe conditional on previous questions (95%)
Joe’s commentary: I haven’t thought about this one very much, but my current view is that the permanent and unintentional disempowerment of humans is very likely to be catastrophic for the potential value of human civilization’s future. Multiplying these conditional probabilities together, then, we get: 65%·80%·40%·65%·40%·95% = ~5% probability of existential catastrophe from misaligned, power-seeking AI by 2070.181 And I’d probably bump this up a bit—maybe by a percentage point or two, though this is especially unprincipled (and small differences are in the noise anyway)—to account for power-seeking scenarios that don’t strictly fit all the premises above.
How this falls out in terms of possible worlds
We can’t build APS by 2070 (35%)
Many systems are possible in these worlds, including far more powerful ones than we have now, just not the ones that Carlsmith describes. Perhaps the last few percentage points of human capability are very hard to train, or perhaps LLMs don’t have world models capable of leading them to think strategically in new environments.
We can build APS but we choose not to (13%)
For some reason we choose not to build such systems, maybe because such powerful systems aren’t economically useful to us or because we ban their use.
It isn’t harder to deploy PS-aligned systems so we probably do (31%)
Here PS-aligned systems are as easy to build as those that aren’t. This is a great world. I hope we live in it. We build PS-aligned systems and they do what we want. Though now we just have to deal with human misalignment but at least they can’t leverage AI recursively increasing to bad ends.
This means that probably any person can call on systems more powerful than the best humans, with strategic planning. I guess it depends on how much they cost to run, but currently that would turn any reader into one of the most productive people they currently know. I find it hard to imagine how quickly the world would change (or how much new regulation would be created that only AIs could navigate)
Misaligned systems don’t cause $1tr of damage before 2070 (7%)
Unclear in such worlds why misaligned systems don’t spin out of control. Perhaps there is some deeper alignment (ie the orthogonality thesis is false), smaller crises cause regulation or APS systems counteract one-another.
These worlds are hard for me to imagine.
Huge damage doesn’t lead to permanent disempowerment (8%)
While 1$T is a worldwide crisis (a quick google suggests that the 2008 crisis caused a comparable loss of growth). I guess that here the crisis causes people to take risk from APS systems seriously and then we avoid permanent disempowerment. Alternatively somehow such systems were never on track to permanently disempower but just caused massive damage without extinction.
I guess these worlds look like the two above sets but just with an additional massive disaster at the front.
Permanent disempowerment somehow isn’t an existential catastrophe (.2%)
I find this hard to imagine, but I guess these are worlds where AI keeps us around in a way that isn’t a catastrophe for us. I wonder if Carlsmith would include a sort of benevolent AI dictator in this bucket. Dogs have a pretty good life, right?
Existential catastrophe (5%)
Whelp. Again it’s worth noting that Joe no longer fully endorses this. If I recall correctly he’s now between 10-15%.
How could these overviews be better?
We are still in early stages so I appreciate a lot of nitpicky feedback
Other resources
Here is an interactive version of his probability tree (screenshot below): https://estimaker.app/_/nathanpmyoung/ai-carlsmith
You can see all the AI probability trees I’ve done here: https://estimaker.app/ai.
Or 80k have done a similar writeup:
Or read his full paper (I recommend watching the video first) - https://arxiv.org/pdf/2206.13353.pdf