


Artificial Intelligence Risk/Reward: My Sketchy Model
All models are wrong, but some are useful

Summary
I have built a forecasting model around Artificial Intelligence (AI) risk/reward
I'm looking for correction. These numbers will change
A quick sketch of the argument
AI can run all functions of run a hedge fund in 2030: 15 - 30 %
AI can do all tasks a 2040 human can do using the internet to the standard of the best humans at the speed of the best humans by 2040: 50 - 70%
If there is AI, the best agents (10x better than the closest), will either be few in number or many:
will be few (<6): ~10%
will be many (6+): ~90% (eg there will be a sea of AI agents)
AI agents will be averse to genocide/slavery: 40 - 80%
In the case of few AI agents, this will still be quite risky, because any bad agent could lead to bad outcomes. In the case of many AI agents, this seems less risky because agents can keep track on one another.
If AIs are willing to enslave or kill humans then they will think it benefits their goals to do so: 50 - 80%
There is about a 2% - 10% chance of human enslavement/extinction by 2050
I think there is a 5% - 20% chance of huge success (e.g. stopping aging by 2050)
I think that those bad outcomes are much worse than the good outcomes, so we still need to really focus on reducing risk and increasing benefit here
My current argument in full is below, as is the model, scroll to the bit you disagree with
Is this work valuable? This is not my job. I did this in about 2 days. Was it valuable to you? Should I do more of it?
Video
I recommend watching this video:
3 min loom video (watch at 1.5 speed)
You can also look around the model. Tell me what you think of the tool.
A longer explanations of the argument
Will we get internet Superhuman AI by 2040? Maybe (65% )
Maybe we get AI that can do any task on a computer as well as the best humans at at least the same speed. This will mean far more scale and likely far more speed (market)
Things that affect this
If AIs are better than humans at science in 2025 (market). It seems likely that if you can make novel discoveries then you can do a lot of other stuff.1
If AI is fully running a hedge fund in 2030. It seems clear to me that a $1bn profitable market neutral hedge fund covers much of what we mean by an Artificial General Intelligence (AGI). Making decisions, finding valuable insights, interacting with human processes at scale etc..
If it turns out that complex tasks require one-shot AIs. I have tried to pull this out with the notion of sub agents. If a hedge fund AI isn’t calling sub agents to do stuff for it, it feels unlikely it could do complex general tasks. Maybe it’s just really good at some narrow kind of prediction.
Heavy regulation - perhaps it becomes illegal to train for certain capabilities and so there aren’t hedge fund or generally superhuman AIs
Can you think of others issues things here? If so, let me know in the comments.

How quickly will AI improve
I don’t really follow much discourse on this, so sorry if it’s facile.
Will AIs want to rapidly increase their abilities? 38%
Will they be able to? 2%
Things that affect this
It seems to me there are two thresholds here2. There is a threshold for how hard it is to self improve and another for how hard it is to be sure the created intelligence will be aligned with the values of the creator.
If is harder to align intelligence than to improve it then a rational being probably wouldn’t. This is the reason for so much fear around AI.
But this seems to also apply to AI themselves. If they are preference maximisers, it will be in their interest to ensure that the intelligences they create/become also want to maximise similar preferences.
So, where are these thresholds?
It seems clear that humans are not intelligent enough to boundlessly improve our own intelligence
It seems likely that alignment is very hard
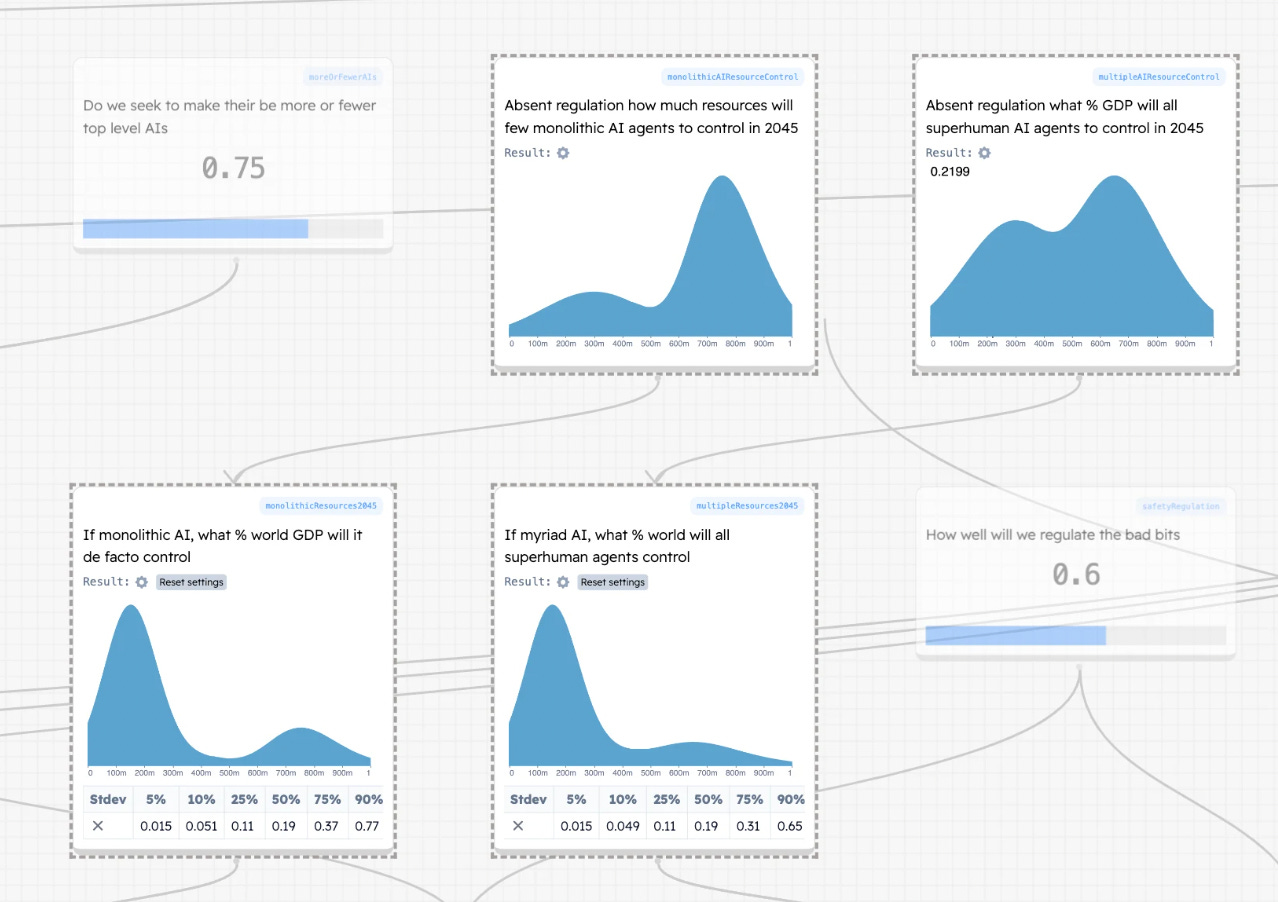
If we get superhuman AI how will resources be controlled?
If (as above) we have something we’d call AGI then do we live in world with many top level agents or few? By top level I mean “how many agents are 10x better than all other agents and humans?”
Monolithic agents3 (1-5) - There are few agents that are best. Not a few models, a few agents - ~10%
Myriad agents (6+) - We live in a big soupy world of many AI agents - ~90%
Things that affect this.
If in 2027 there is already one LLM model that is waaay more competent (10x) than all the others (market). If this is already the case in 2027 it seems more plausible that it will be later
How able are LLMs to improve themselves? (above) If very, then it seems like <6 is likely a few models outstrip all the others. To me it seems AI improvement is the alignment problem again. So I think that many agents is more likely than a very small number - rapid self improvement while maintaining the same identity will be hard.


What about the economic factors? Do these incentivise the the creation of ever more agentic or intelligent models? I sense that ever more agentic models aren’t necessarily most profitable. You want someone to execute tasks, not replan your whole life (Katja Grace made this point4)
What does regulation achieve here? Is this pushed one way or the other?
What other markets could we currently have here?
How will the resources be distributed in this case
If the most powerful agents are few, I guess they will control most of the resources.
I guess this is because having fewer agents to me suggests that you can’t make more - that for some reason they are either suppressing others or are accelerating ever faster. It seems that resources are more likely to be out of human control
If there are many (6+) top level agents then I am really pretty uncertain.
Here it feels like agents might be little more powerful than humans, or there might be a really wide spread of agents
Things that affect this
Better regulation. We might stop agents controlling resources directly. I don’t really know what this means, so feel free to challenge on it
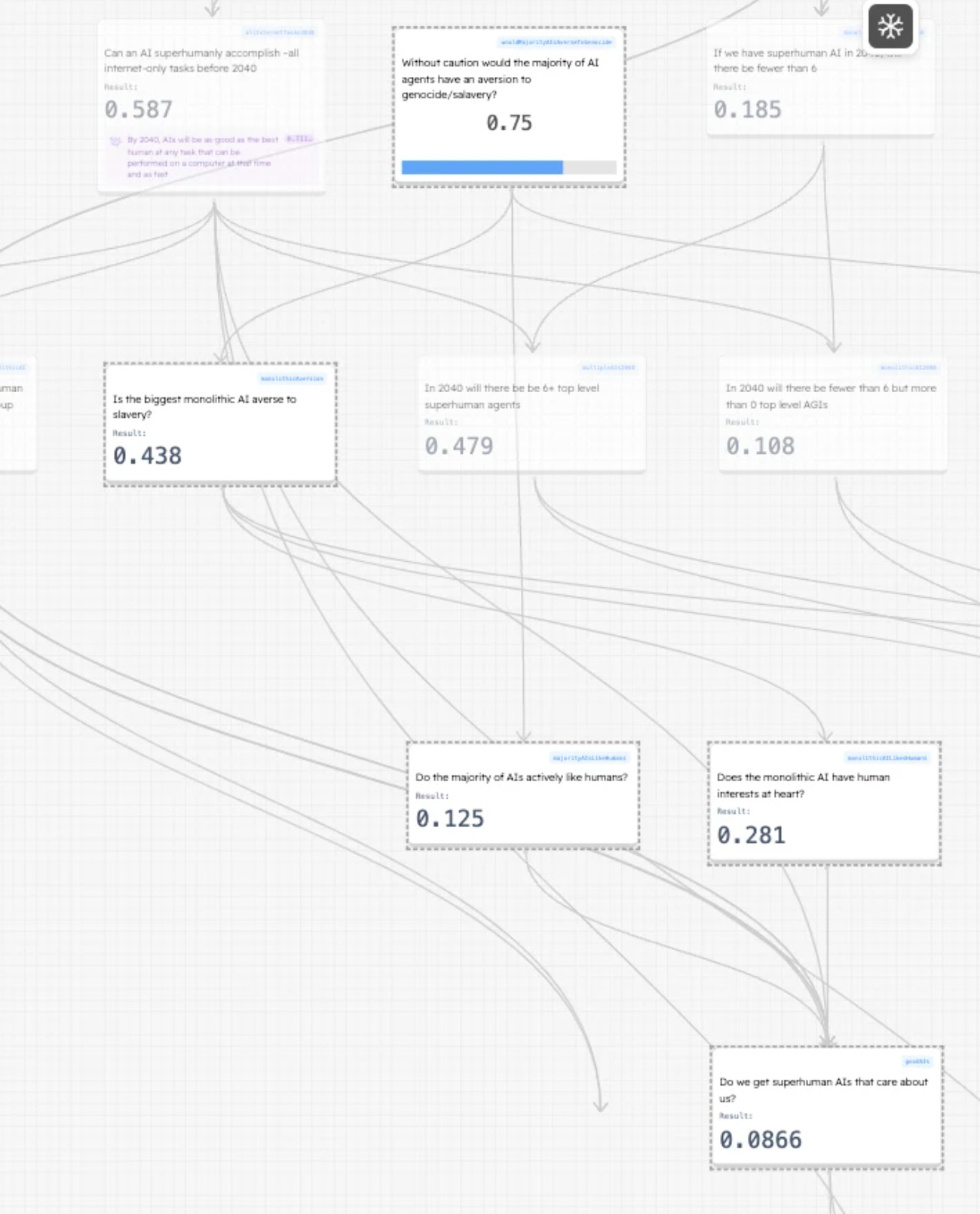
Will AIs be very good or very bad?
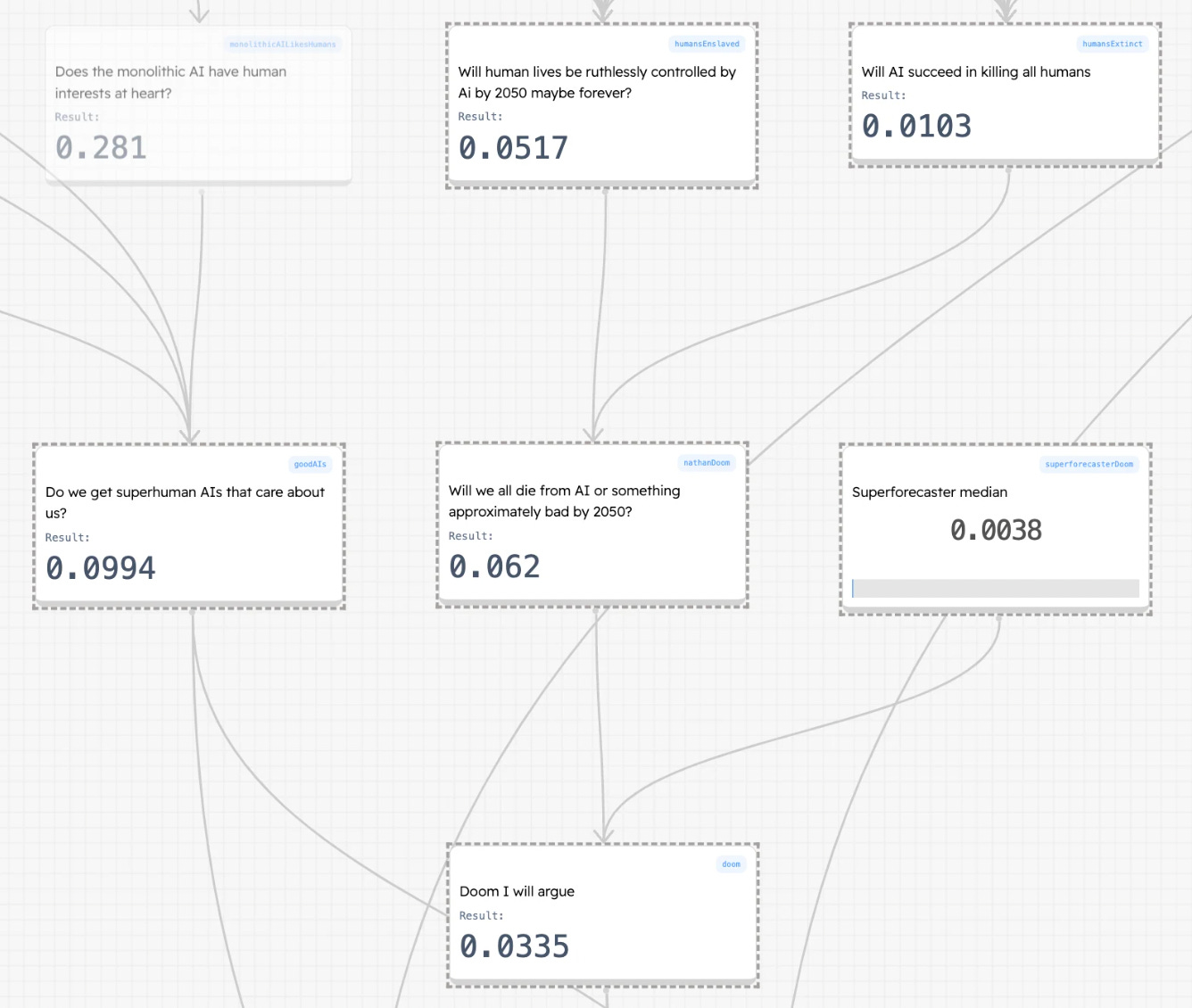
Will AI agents avoid plans that involve slavery/genocide? This seems important because the reason that we don’t do these things is because they are repulsive to us. They don’t feature in our plans, even if they might make the plans more likely to succeed. Will this be the case for AIs
Monolithic - 45%
Myriad - 85%
What affects this
Without caution I still think they probably will have this aversion
My sense so far is that LLMs have pretty human preferences. They need to be adversarially prompted to be otherwise. It is not clear to me that more intelligence pushes away from this. Now I’m not remotely confident enough, but I think the *evidence* against this is just “ruthless things would be more ruthless* but I think we should update against that. LLMs so far are not that ruthless
Companies do not want AGIs that occasionally express preferences for genocide. This is against their bottom line
With regulation I think this problem becomes better. I think companies will be well incentivised to ensure that agents dislike awful answers like slavery or genocide
I sense that monolithic AIs are just much worse for this. Feels like a much more alien world in which the most powerful AIs are way more powerful than all the others. Feels like they might be more alien/ruthless
My sense is that most of us think that if AGI doesn’t go badly it will go really well. But we do not say this often enough.
How likely are AGIs to, on average, really want good things for us? These numbers are pretty uncertain, even for me
Monolithic - 28%
Myriad - 13%
What affects this?
If monolithic AI is not bad, it seems more likely to me to be really good, because it is more like a single agent
I think it’s pretty unlikely that myriad AI is good as such. There is so much of it and it all has its own little goals. I don’t but it.
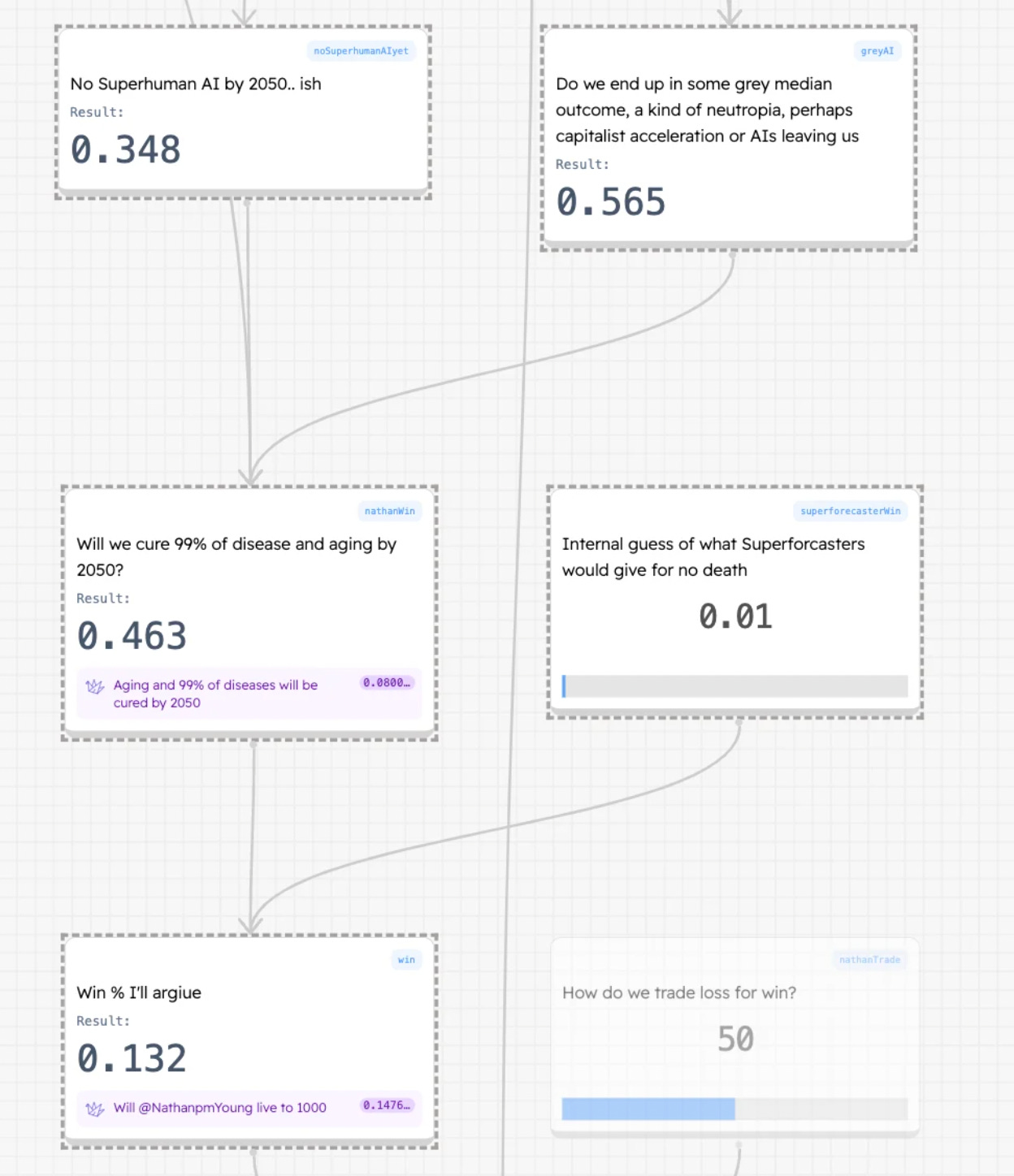
Interlude: Do we end aging by 2050?
Aging post ~25 is bad
A nice example of a win is whether we can cure aging and ~all disease
I think I’ll say 13%. Most of this comes from my “neutopia” outcome, where we somehow neither end in disaster or ultimate success. This world still has AIs and therefore increased technology but they’re neither like us nor what to enslave us. The forecaster in me says this occupies a big part of the distribution
My bodge factor. I don’t like numbers that I feel off with, but also I don’t like hiding that I’m doing that. I think the superforecasters aren’t gonna give more than 1% chance of ending aging. Take that with my 43% and we end up at 13%
Will I live to 1000 (market)
I think there is a good discussion here about tradeoffs. The model isn’t really robust to what risk = what reward, but I think a better version could be. I think that slowing AI does push back the date at which we end aging. Ideally I hope we can find a way to cut risk but keep benefit.
What current markets could I create for this? Maybe something about protein folding?
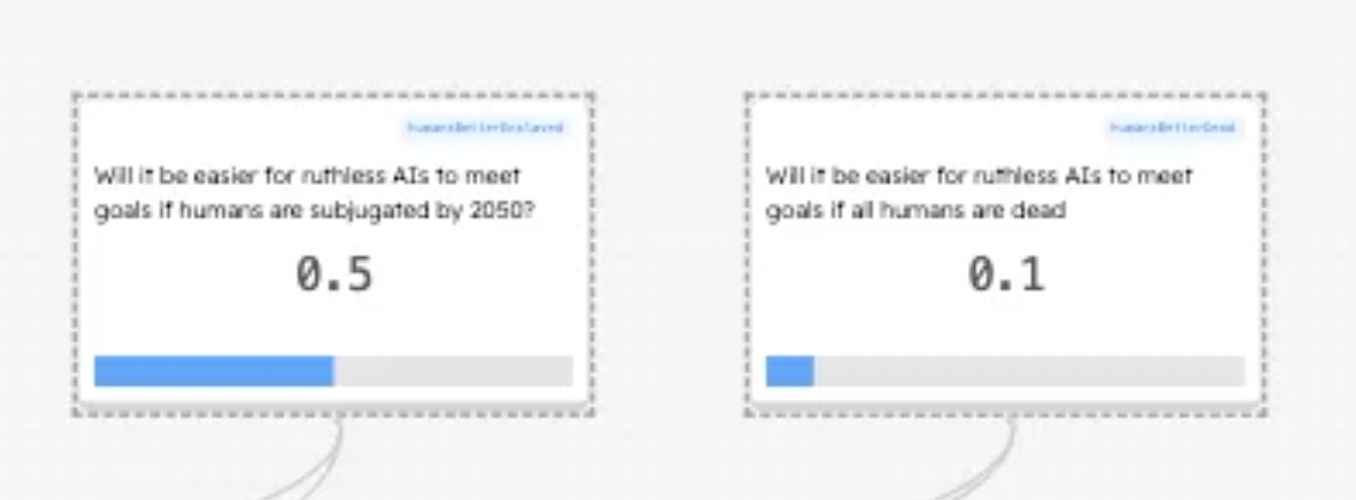
And now a word from our sponsors
Will AIs have plans that are benefited by us being enslaved or dead
Enslaved - 50% Seems clear to me that AIs might think we might be useful or just not really care enough to kill us all but not want us to get in the way
Dead - 10% There seems some chance that the best way to not have us be in the way is to kill us all
What affects this
I can’t really think of good arguments here.
90% seemed too high, but I could be pushed up

If there are many AIs will they coordinate against humans? Maybe 42%
If there are many AI agents will they coordinate against humans so as to enact coup attempts. Maybe
Things that affect this
It seems natural to me that AI agents will be more similar and comprehensible to one another than to us so will make better allies with each other than with us
Regulation of AI to AI communication channels
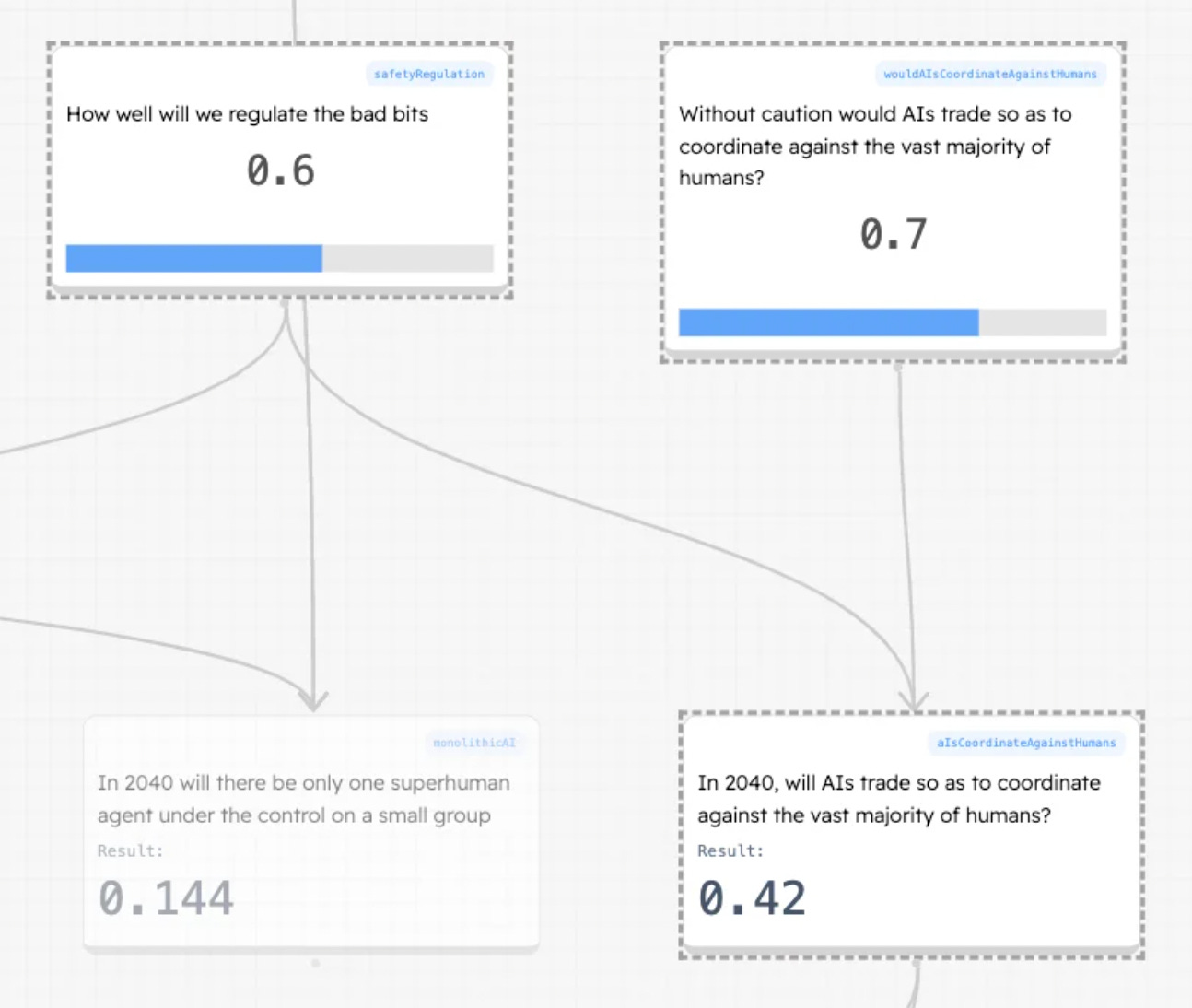

Will they kill or enslave us by 2050? 3%
Will they have resources, want to kill or enslave us, be able to coordinate if necessary and run a successful coup? 3%
Things that affect this
All of the above. Most notably
I have pulled myself a bit towards the superforecaster median because that usually does good things for my forecasts
Will AI be easier than I think
Will AIs hold resources more than I think
Will they be more ruthless than I think
Will we end up in Monolithic world
Are coups easier than I think?

Broad Points
Monolithic Vs Myriad
It seems pretty important whether we are heading towards a world where there are a few AIs that control almost everything controlled by AIs or many. This isn’t my insight, but the latter case seems safer because AIs can be a check on one another.
Is this a weakest or strongest link problem?
AIs still have to get other AIs to do stuff for them and for any awful action there will likely be a chain of AIs which need to do it. So whereas many seem to think you only need one bad AI for stuff to go wrong, I think you only need one good AI for stuff to go okay! Only one AI needs to report that it’s involved in illegal activity and then the whole scheme breaks. This is doubly so for things which involve coding, which is notoriously brittle and where LLMs will not have lots of training data - there just aren’t that many large public repositories to crawl, I think.
In this case, it’s not a weakest link problem, it’s a strongest link. Rather than any AI being bad, you only need one to be good. This seems pretty encouraging.

P(Doom) is unhelpful
Christ Jesus came into the world to save sinners, of whom I am the foremost.
I am one of the worst offenders for talking about P(doom) but writing this has made me think how poor a practice it is. Rather than us comparing things we can know soon we end up wandering the moors arguing over number that probably will never be falsifiable until it’s fine or too late.
I think it's much more productive to talk about the next 3 or so years and try and get a picture of that. Because honestly, that too is likely to be flawed, but at least we have a hope of doing it accurately.5
Key Levers
Things that seem worth investigating
If you have rapid takeoff you might want only 1 company working, BUT if you have gradual takeoff you might want many AIs of a similar level
Make AIs want to whistleblow. Train AIs to report to channels (or eachother) if they suspect they are involved in malicious activity.
Avoid AIs easily being able to control large amounts of resources. Require humans to be involved in transactions above a certain size
Conclusion
Where do you think I am wrong?
Was this valuable? Would you have paid for this?
If you like this, read the model!
But Nathan, that node doesn’t go anywhere. Yeah I know. I didn’t know how to do it
Thanks to Keith Wynroe for his input on this point.
What are the proper names for these? Presumably someone has made some up
I like Katja so I’m biased but I really liked her EAG talk. I changed a number of views and also it encouraged me that I could think about this well
I think you're far too high (10x) for AI killing/enslaving us all, conditional on it being able to. There's a really high opportunity cost from doing so. For an intuition, which of your goals do you think the optimal/most efficient/most likely to succeed path to achieving them (ignoring moral constraints) involves world domination? For a fuller version of this argument: https://rootsofprogress.org/power-seeking-ai
The rest seems reasonable at first reading to me.